最近接到一个项目,需要计算大约 20 万个事件的 CAR。这是一个 CPU 密集型的任务,并行计算可以大大提高效率。于是我又重新捡起了进程、线程这些概念😒 每次都是用的时候看看文档,是时候进行一个系统性的梳理了🤣
进程,线程与协程
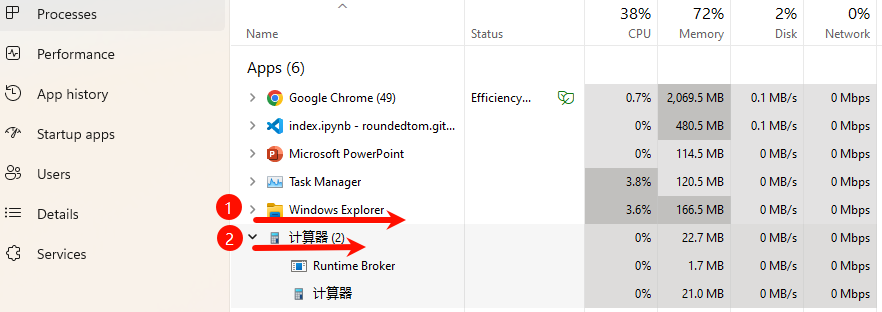
进程是一个程序在一个数据集中的一次动态执行过程,可以简单的理解为“正在执行的程序”,它是 CPU 资源分配和调度的独立单位。在 Windows 中可以通过任务管理器查看当下进程运行情况,比如我们打开文件资源管理器,就开了一个文件资源管理器进程(箭头1)。任务管理器显示了这个进程占用的 CPU、内存、网络等资源。
进程之间相互隔离,每个进程拥有自己独立的内存空间、数据栈以及其他资源。因此现代应用程序一般会开启多个进程,尤其是在复杂的、资源密集型的应用中(例如网页浏览器、电子邮件客户端、开发工具等),这样可以提高稳定性、安全性和性能,一个进程崩溃也不会影响其他进程。比如我们打开一个计算器,操作系统开启两个进程(上图箭头2)。其中,runtime broker 是 Windows 操作系统中的系统进程,用于管理 UWP 应用的权限和安全。
进程的局限是创建,撤销和切换的开销比较大。同时,由于进程之间相互独立,进程间的通信比较复杂。另外,多进程并行运行时系统开销比较大。
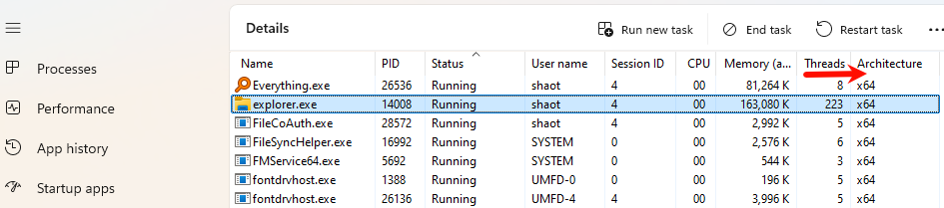
线程是进程之后发展出来的概念,线程也叫轻量级进程,它是一个基本的 CPU 执行单元,也是程序执行过程中的最小单元。如果说进程是一个任务,线程可以理解为子任务。线程由线程 ID,程序计数器,寄存器集合和堆栈共同组成。每个进程内都有一个主执行线程,它无需由用户创建,而是由系统自动创建。用户根据需要在应用程序内创建其他线程,多个线程并发的运行于同一个进程中,共享进程内存。在 Windows 任务管理器中可以点击 details 查看线程。比如我们刚刚开启的文件资源管理器进程中,有 223 个线程在并发运行(下图箭头处)。
线程的优点是减少了程序并发执行时的开销,提高了系统的并发性能;缺点是线程没有自己的系统资源,只有运行时必不可少的资源,但同一进程内的各线程可以共享进程所拥有的系统资源。另外,多个线程并发的运行在一个进程中,一个线程的崩溃可能影响整个进程。
最后简单提一下协程。协程是一种用户态的轻量级线程,又称微线程,协程的调度完全由用户控制,人们常常将协程与子程序(函数)比较着理解。子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。协程与多线程相比,其优势在于协程的执行效率极高,因为是子程序切换不是线程切换,由程序自身控制,因此没有线程切换的开销。
多进程 VS 多线程
程序任务可以简单分为两类:CPU 密集型和 IO 密集型。CPU 密集型任务是指程序的主要工作是进行大量的计算,比如加密、解密、大数据处理、矩阵运算等等,这类任务会占用大量的 CPU 资源。IO 密集型任务是指程序的大部分时间都在等待外部输入/输出,比如文件读写、网络请求、数据库查询等等,而不是占用 CPU 进行计算。多进程和多线程都可以实现多任务,但两者有不同的适用场景。其原因在于 Python 中存在一个全局解释器锁(GIL),这把锁只允许解释器中一次运行一个线程,也就是说同一时间只能有一个线程执行 Python 代码。
CPU 密集型任务适合多进程。Python 中的 GIL 只允许一个线程执行 Python 字节码。因此,对于 CPU 密集型任务,线程即使是并发执行,也不能真正利用多核 CPU 来加速运算,因为 GIL 限制了同一时间只能有一个线程运行 Python 代码。而多进程可以绕过 GIL。因为每个 Python 进程都有自己的解释器和 GIL,多个进程可以在多核 CPU 上并行运行,并充分利用 CPU 资源,提高运算效率。
IO 密集型任务适合多线程。IO 操作比如等待数据从网络传输,会让线程进入“阻塞”状态。此时,Python 解释器会释放 GIL,允许其他线程运行。因此,即使有 GIL 的限制,IO 密集型任务的多线程仍然能够并行处理多个任务,因为大部分时间线程都在等待外部资源,而不是执行 Python 代码。此外,线程的创建和切换开销比较小,适合大量并发的 IO 操作,例如处理多个网络请求或文件读写。Python 可以在等待 IO 操作时切换到其他线程继续执行。
Python 的多进程实现
Python 提供了 multiprocessing 模块来实现多进程。multiprocessing 模块的设计灵感来自于 threading 模块,但它提供了更高效的并发执行方式。通过 multiprocessing 中的 Process 类可以快速创建一个子进程。
Process 类
import osfrom multiprocessing import Processimport randomdef task1(l: list ) -> list :return [number** random.randint(0 ,3 ) for number in l] def task2(l: list ) -> list :print (f"父进程ID: { os. getppid()} " ) print (f"工作进程ID: { os. getpid()} " )return [number** random.randint(0 ,3 ) for number in l] if __name__ == "__main__" :print (f"主进程ID: { os. getpid()} " )print (f"主进程运行结果: { task1([2 , 4 , 6 , 8 ])} " )= Process(target = task2, args= ([1 , 3 , 5 , 9 ],)) # 创建子进程 # 启动进程 # 阻塞主进程,等待子进程执行完毕 print ("工作任务全部完成" )
主进程ID:2632
主进程运行结果:[8, 1, 216, 1]
父进程ID:2632
工作进程ID:25460
子进程是否运行:True
工作任务全部完成
上面的代码中,我们利用 Process 类创建了一个子进程。创建子进程时,需要传入一个执行函数和函数的参数。通过 os.getppid() 可以查看父进程 ID,可以发现子进程的父进程就是我们的主进程。start() 方法用于启动子进程,join() 方法会阻塞主进程,直到子进程执行完毕,后续代码才会运行。
再观察一下上面的代码,函数 task2 有返回值,但子进程默认不会返回值给主进程,因为每个进程有自己独立的内存空间。要获取子进程的返回值,可以通过 Pool 类来实现。Pool 类也可以用于批量创建子进程。
Pool 类
Pool 是一个高层次的 API,用于管理多个进程,并且可以方便地获取每个子进程的返回值。Pool 类中最常用的是 map() 和 apply_async() 方法。它们的主要功能都是用于分发任务到进程池中的多个进程并获取结果,但它们的行为方式、适用场景和返回结果的方式有所不同。
map()map() 方法是同步执行的,其行为与内置的 map() 函数非常相似。它将一个函数应用到一个可迭代对象的每个元素上,并在所有任务完成后一次性返回结果列表。在下面的代码中,通过给 Pool 类传入需要创建的子进程数量(默认是 os.cpu_count())来创建进程池。map() 会等待所有进程完成后一次性返回结果。
from multiprocessing import Poolimport randomimport timedef task(x):print (f"进程 { os. getpid() } 启动。。。 \n " )= time.time()1 , 3 ))= time.time()print (f"进程 { os. getpid() } 耗时 { end- start} 秒 \n " )return x * xif __name__ == "__main__" :with Pool(processes= 3 ) as pool:# 向进程池提交任务,并获取返回值 = pool.map (task, [1 , 2 , 3 , 4 ])print (results)print ("所有任务执行结束" )
进程45175启动。。。
进程45177启动。。。
进程45176启动。。。
进程45176耗时1.0004842281341553秒
进程45176启动。。。
进程45175耗时3.0004098415374756秒
进程45177耗时3.000214099884033秒
进程45176耗时3.0003042221069336秒
[1, 4, 9, 16]
所有任务执行结束
观察输出结果可以发现,map() 将输入的可迭代对象任务依次分发给进程池中的进程,并且会阻塞主进程直到所有任务完成。总结一下 map() 的特点:
同步执行:主进程会等待所有子进程执行完成后,才继续执行后续代码。
顺序返回:结果按照输入顺序返回,和输入顺序保持一致。
适用于批量任务:有一组任务需要并行处理,并且希望一次性获取所有结果。
apply_async()与 map() 不同,apply_async() 是异步执行的,它可以让主进程继续执行而不必等待子进程完成。apply_async() 返回的是一个 AsyncResult 对象,通过 get() 方法可以获取任务的执行结果。
from multiprocessing import Poolimport randomimport timedef task(x):print (f"进程 { os. getpid() } 启动。。。 \n " )= time.time()1 , 3 ))= time.time()print (f"进程 { os. getpid() } 耗时 { end- start} 秒 \n " )return x* xif __name__ == "__main__" := []with Pool(processes= 3 ) as pool:for n in [1 , 2 , 3 , 4 ]:= pool.apply_async(task, (n,))# 主进程可以继续执行其他任务 print (f"主进程 ID 是: { os. getpid()} " )# 通过 result.get() 获取子进程的返回值 = [result.get() for result in result_objs]print (results)print ("任务执行结束" )
进程49116启动。。。
进程49118启动。。。
进程49117启动。。。
主进程 ID 是:2632
进程49116耗时2.0006251335144043秒
进程49117耗时2.000253438949585秒
进程49116启动。。。
进程49118耗时3.0007407665252686秒
进程49116耗时2.000547170639038秒
[1, 4, 9, 16]
任务执行结束
在上面的代码中,使用 apply_async() 来异步执行任务,子进程运行不会阻塞主进程。总结一下 apply_async 的特点:
异步执行:主进程不会等待任务完成,可以继续执行其他操作。如果需要,可以通过 AsyncResult.get() 方法获取任务结果。
结果不按顺序返回:由于是异步执行的,多个任务可以并发运行,结果顺序与输入顺序不一定保持一致。
适用于独立的异步任务:非常适合需要在后台并行处理多个独立任务,并且主进程需要在处理其他任务时逐步获取结果的情况。
进程间通信
multiprocessing 模块提供了多种方式实现进程间通信(IPC),包括队列(Queue)、管道(Pipe)、Value、Array 和 Manager 等等。其中队列和管道使用简单、灵活,也是官方文档推荐的进程间通信实现方法。
QueueQueue 是 multiprocessing 模块中提供的一种进程间通信机制,允许多个进程安全地传递消息。它实现了先进先出(FIFO)的数据结构,非常适合需要在多个进程之间共享数据的场景。
我们可以使用 Queue 类来创建队列实例:
from multiprocessing import Queue= Queue(maxsize= 5 )"Hello world!" )print (q.get())
上面的示例代码使用 Queue 类创建了一个队列实例,maxsize 参数用来控制队列的大小,默认无限制。我们可以使用 put 方法将数据放入队列,使用 get 方法从队列中获取数据。
put() 和 get() 方法的默认行为是阻塞的。如果队列已满,put() 会等待,直到有空间可用;如果队列为空,get() 会等待,直到有数据可用。我们看下面的例子:
import timefrom multiprocessing import Process, Queuedef worker(q):for i in range (5 ):1 )f"Messege { i} from worker." )if __name__ == '__main__' := Queue(maxsize= 3 )= Process(target= worker, args= (q,))for _ in range (5 ):print (q.get())
Messege0 from worker.
Messege1 from worker.
Messege2 from worker.
Messege3 from worker.
Messege4 from worker.
可以通过设置 block=False 参数来实现非阻塞操作,同时抛出标准库 queue 模块中的 queue.Empty 和 queue.Full 异常以指示超时。比如下面的例子:
import timefrom multiprocessing import Process, Queuefrom queue import Empty, Fulldef worker(q):for i in range (5 ):try :# 非阻塞放入 f"Messege { i} from worker." , block= False )except Full:print ("Queue is full, waiting ..." , flush= True )if __name__ == '__main__' := Queue(maxsize= 3 )= Process(target= worker, args= (q,))for _ in range (5 ):try :# 非阻塞取出 print (q.get(block= False ))except Empty:print ("Queue is empty." , flush= True )
Queue is empty.
Queue is empty.
Queue is full, waiting ...
Messege0 from worker.
Messege1 from worker.
Messege2 from worker.
总结一下,Queue 的特性如下:
线程安全:Queue 内部实现了锁机制,可以安全地在多个进程间共享,避免数据竞争。
阻塞与非阻塞:可以选择阻塞或非阻塞方式来接收或发送消息。
灵活性:Queue 中可以放入任何可以被 pickle 序列化的对象,包括基本数据类型、列表、字典等。
PipePipe 是 multiprocessing 模块中提供的一种进程间通信机制,允许两个进程之间通过一个双向的管道进行数据交换。它非常适合需要两个进程直接通信的场景,使用简单且高效。
我们可以使用 Pipe 类来创建连接实例:
import multiprocessing= multiprocessing.Pipe()
在上面的示例代码中,parent_conn 和 child_conn 是通过 multiprocessing.Pipe() 创建的两个连接对象,用于实现进程间的通信。其中:
parent_conn 代表管道的“父”端,通常用于主进程。主进程可以通过 parent_conn 来接收子进程发送的数据,使用 recv() 方法。child_conn 代表管道的“子”端,通常用于子进程。子进程可以通过 child_conn 发送数据到主进程,使用 send() 方法。
这两个连接是相互独立的,尽管它们连接在一起形成一个管道,但它们可以在不同的进程中独立使用。下面我们来看一个例子:
import multiprocessingimport timedef worker(pipe_conn):"Hello from worker!" )5 )"Another messege from worker." )# 关闭链接 if __name__ == "__main__" := multiprocessing.Pipe()# 创建并启动子进程 = multiprocessing.Process(target= worker, args= (child_conn,))# 主进程接收消息 print (parent_conn.recv())print (parent_conn.recv())
Hello from worker!
Another messege from worker.
在上面的代码中,子进程启动执行,向管道发送信息 “Hello from worker!”,然后 sleep,主进程获取信息打印出 “Hello from worker!”,然后阻塞。5 秒后子进程再次发送信息,主进程接受消息打印出 “Another messege from worker.”。
可以发现,管道中接收和发送操作默认是阻塞的,意味着如果没有数据可读,接收操作会等待,直到有数据到来。不过我们可以通过设置 timeout 参数来处理阻塞情况,或者使用 poll() 方法来检查数据是否可读。
import multiprocessingimport timedef worker(pipe_conn):"Hello from worker!" )10 )"Messege after delay." )# 关闭链接 if __name__ == "__main__" := multiprocessing.Pipe()# 创建并启动子进程 = multiprocessing.Process(target= worker, args= (child_conn,))# 主进程接收消息 while 1 :if parent_conn.poll(timeout= 1 ): # 检查是否有数据可读 print (parent_conn.recv())else :print ("No message received within timeout" )break
Hello from worker!
No message received within timeout
上面的示例代码使用 poll 方法对管道中的数据进行判断,检查是否有数据可读,从而避免了主进程阻塞。
总结一下,Pipe 的特性如下:
双向通信:通过管道的两个端点,可以实现双向数据传输。当两个进程需要频繁交换数据时,Pipe 是一个理想的选择
接收和发送操作默认是阻塞的,意味着如果没有数据可读,接收操作会等待,直到有数据到来。
对于小量数据的传输,Pipe 提供了较低的延迟和较高的传输速度。